


Bij iedere SEO-audit van de site zijn logbestanden van groot belang. Ze zijn nodig om te begrijpen hoe de site gevonden wordt en in kaart wordt gebracht door de diverse crawlers van zoekmachines.
Voordelen t.o.v. de bekende web analytics tools
Bijna alle computers en programma’s gebruiken logfiles, zo ook webservers. In de logfiles wordt belangrijke informatie opgeslagen, zoals de data en tijdstippen van bezoeken aan de site, het gebruikte IP-adres, de naam van de bezochte pagina, de browser-versie en besturingssysteem van de bezoeker, en cookie-informatie. De logfiles leggen niet alleen de gegevens van reguliere bezoekers vast, maar ook die van de crawlers (ook wel spiders of bots genoemd) die de zoekmachines zoals Google gebruiken om de site in kaart te brengen. Dat is iets wat geen enkele web analytics-tool gebaseerd op JavaScript kan doen. Een bijkomend voordeel is dat er geen extra vereisten zijn om logfiles te gebruiken: Er hoeft geen JavaScript toegevoegd te worden op iedere pagina die gelogd moet worden, wat configuratiefouten en een vertraging bij het openen van de pagina voorkomt. Ook zijn er geen speciale ‘tags’ nodig, wat bij het gebruik van JS vaak wel het geval is. Desondanks zijn JavaScript-tools over het algemeen onmisbaar, maar logfiles zijn een welkome aanvulling en voor sommige SEO-audit activiteiten een beter alternatief.
Met name een analyse van de crawl-activiteiten kan waardevolle inzichten opleveren over het functioneren van de site en de individuele pagina’s. Het gedrag van de crawlers verandert regelmatig, dus het heeft geen zin om iedere dag te speuren naar kleine wijzigingen. Logbestanden komen vooral van pas bij het opsporen van trends over de langere termijn. Zo kan bijvoorbeeld geanalyseerd worden of de activiteit van de crawlers op de site een stijgende of dalende lijn vertoont en welke pagina’s op de site het vaakst worden gecrawld.
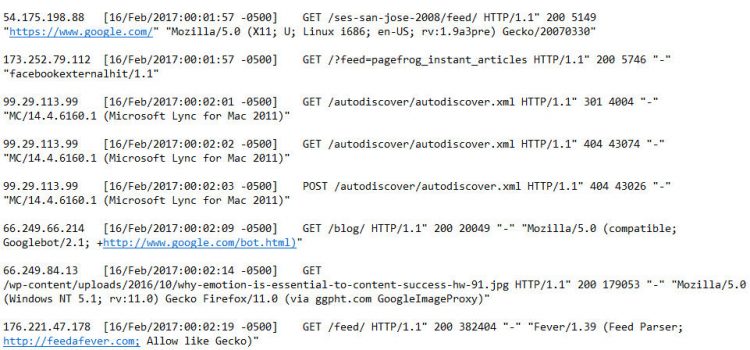
Overzicht van crawler activiteiten.
Logbestanden zijn buitengewoon uitgebreid en registreren vrijwel alle activiteiten, dus kunnen veel nuttige informatie bevatten voor een SEO-scan. Het is dus zaak om die bestanden in handen te krijgen. Indien de site in eigen huis wordt beheerd, zal dat geen probleem zijn, maar ook in het geval dat de website wordt gehost door een derde partij (ISP) zijn de bestanden meestal toegankelijk. Informeer naar de beschikbaarheid ervan en vraag ook hoe lang de logfiles bewaard blijven. Vaak beschikt de provider over logfiles die ver teruggaan in de tijd, waardoor de analyse kan worden uitgevoerd over een langere periode, wat de betrouwbaarheid ten goede komt.
Crawl budget optimalisatie
Een voor de hand liggende manier om logbestanden te analyseren is met behulp van Microsoft Excel. Hiervoor is enige handigheid nodig bij het importeren, filteren en sorteren van de data. Een geïmporteerd logbestand levert een werkblad op met veel rijen en kolommen. Door filters te gebruiken is het mogelijk om inzichtelijk te maken welke webcrawlers toegang hebben tot de site en met welke regelmaat. Het crawlen van de zoekmachines kent bepaalde regels. Eén van de belangrijkste is het zogenaamde ‘crawl budget’, het aantal pagina’s per site die de crawler per dag doorzoekt. Het ‘crawl budget’ is geen onveranderlijk getal, maar hangt af van een aantal verschillende factoren. Er wordt rekening gehouden met het negatieve effect dat het crawlen kan hebben op de snelheid van de host. Daarom wordt er een hiërarchische lijst van pagina’s opgesteld, onder andere op basis van de PageRank. De crawl-prioriteit van de secties en pagina’s is daarnaast ook te beïnvloeden met behulp van de XML-sitemap.
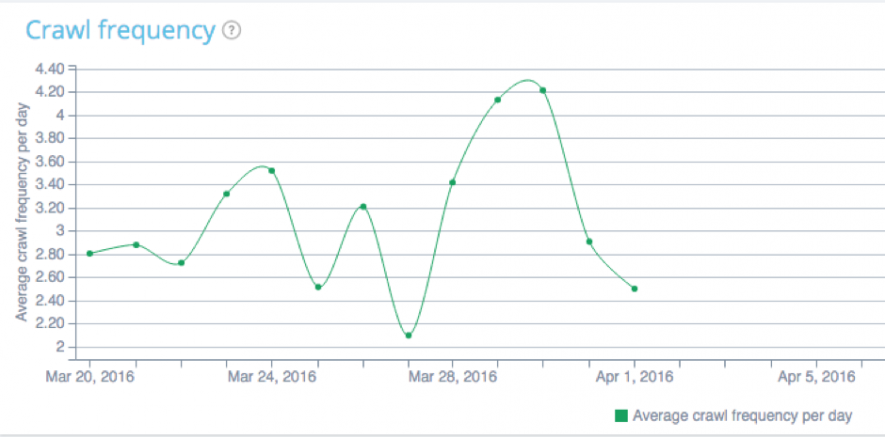
Crawl frequentie in kaart gebracht.
De pagina’s op de crawllijst worden regelmatig opnieuw gecrawld, en daarbij wordt altijd begonnen met de pagina’s die de hoogste prioriteit hebben. Op het moment dat de activiteit van de crawler leidt tot vertraging op de host wordt het crawl-proces gestopt. Zodoende worden de belangrijkste pagina’s het vaakst opnieuw gecrawld en is het mogelijk dat minder hoog scorende pagina’s met regelmaat worden overgeslagen. Daarom is het van belang om te weten hoe de crawlers hun tijd op de site besteden. Het kan voorkomen dat de zoekmachines door een beperkt ‘crawl-budget’ belangrijke pagina’s van de website niet vaak genoeg crawlen. Een analyse van de logfiles kan dan buitengewoon zinvol zijn. Er wordt zichtbaar welke secties en pagina’s worden gecrawld en de frequentie waarmee dat gebeurt. Maar ook wordt duidelijk hoe de crawler zijn tijd besteed op de site en aan welke onderdelen van de site hij onnodig tijd verliest. Het is bijvoorbeeld mogelijk dat er irrelevante of dubbele URL’s worden gecrawld. Bijvoorbeeld ‘URL-parameters’, die vaak worden getagd aan meerdere pagina’s als zij deel uitmaken van dezelfde marketingcampagne. Om deze URL’s voortaan uit te sluiten van het crawl-proces, kan men (bij Google) inloggen op de Google Search Console, daar ‘Crawl’ te selecteren en vervolgens ‘URL-parameters’. Zo is het mogelijk om URL-paramaters te configureren en uit te sluiten van het crawlen, waardoor er meer tijd overblijft voor het doorzoeken van belangrijke pagina’s.
HTTP response codes
Een ander belangrijke bron van informatie uit de logbestanden zijn de ‘response codes’ van de webserver. Door het zoeken naar niet bestaande pagina’s gaat kostbare tijd verloren. Wanneer men in Excel de logbestanden sorteert op deze kolom, wordt zichtbaar hoe vaak een bepaalde response code wordt gegenereerd door activiteit van de crawlers.
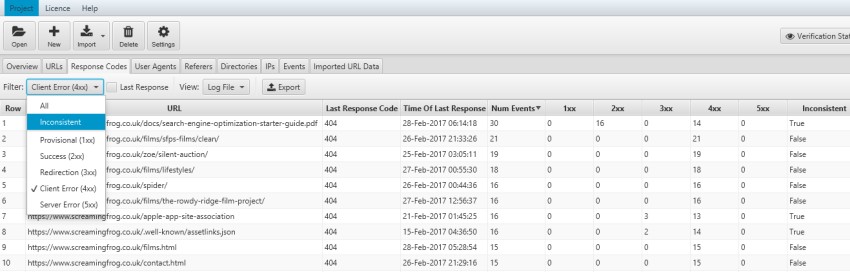
Overzicht 404 foutmeldingen
In principe is de enige goede response code ‘200’, de melding dat de pagina is gevonden, al zijn ‘redirect’ codes (300, 301, 302), die uiteindelijk uitkomen bij een code 200 ook in orde, mits het er niet te veel zijn. Foutcodes als 404 en 500 wijzen op andere problemen met de site.
Tools
Zijn er tools op de markt om dit hele proces te vergemakkelijken? Jazeker. Mijn voorkeur gaat uit naar Screaming Frog. Dit is een freemium spider tool die je kunt downloaden hier. De gratis versie heeft een limiet van 500 URLs per crawl. Voor kleine sites is dit doorgaans al genoeg.
Vergeet de logbestanden niet…
Logbestanden kunnen een schat aan gegevens bevatten die van cruciaal belang kunnen zijn voor de search performance van de website. Het gebruik van logbestanden, naast web-based analytics, helpt mee om de ‘conditie’ van een site vast te stellen en kan helpen bij het oplossen van problemen die de site ondervindt.