


Technische SEO wordt vaak achtergesteld ten opzichte van dingen zoals content creation, social media en link building. Ik ben toch altijd van mening geweest dat er veel mogelijkheden zijn om verkeer te vermeerderen door binnen te kijken i.p.v. naar buiten. Een van de belangrijkste aspecten hiervan voor mij is ervoor zorgen dat je website zo toegankelijk mogelijk is voor zoekmachines.
Het is eigenlijk vrij simpel – als de zoekmachines je website niet efficiënt kunnen crawlen, zal je waarschijnlijk geen rankings krijgen. Zelfs links en social shares lossen ernstige toegangsproblemen niet op dus het gevolg is dat je link building er ineffectief uit zal zien. Dit is het laatste wat je wilt, aangezien link building sowieso al moeilijk kan zijn, je wil jezelf niet kreupel maken voordat je überhaupt begonnen bent.
Dus ga ik in deze post vertellen over de belangrijkste punten waar je op moet letten als het gaat om het toegankelijk maken van je website. Een toegankelijke website betekent dat alle target pagina’s geïndexeerd worden en de ge-ranked kunnen worden voor je doel zoekwoorden.
Om het logisch te houden heb ik de post verdeeld in drie hoofdpunten:
- Crawlen
- Indexeren
- Ranking
Crawlen
Het eerste waar we op moeten letten is dat al onze doel pagina’s gecrawld kunnen worden door de zoekmachines. Ik zeg ‘doel pagina’s’ omdat er situaties voor zullen komen waarin je het crawlen van bepaalde pagina’s wilt stoppen, waar ik later verder op in zal gaan.
Voor ik dit doe, laten we kijken hoe we onze website geschikt maken voor crawlen en hoe we naar mogelijke problemen kunnen zoeken.
Goede site architectuur
Een goede website architectuur is niet alleen goed voor zoekmachines, maar ook voor gebruikers. Simpel gezegd, je wilt er zeker van zijn dat jouw meest belangrijke pagina’s makkelijk te vinden zijn, het liefst binnen een paar klikken van de homepage. Dit werkt goed vanwege een aantal redenen:
- Gewoonlijk is je home de pagina waar het meest naartoe wordt gelinkt en daarom kan deze veel PageRank door de rest van de site laten vloeien.
- Gebruikers zullen je hoofdpagina’s makkelijk kunnen vinden – waardoor de kans dat ze vinden wat ze willen en daardoor klant worden groter wordt.
Om uit te leggen hoe dit er eigenlijk uit ziet, hieronder een voorbeeld van een simpele structuur:
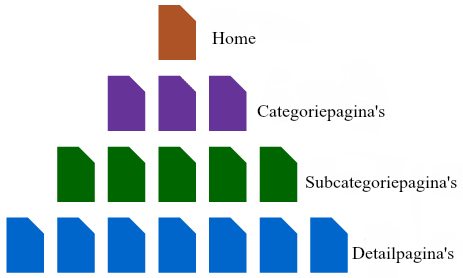
Als je een e-commerce website bezit zouden de detail pages in dit voorbeeld je productpagina’s zijn. Dit is een logische structuur en een die wordt aangeraden voor kleine tot middelgrote websites.
Maar wat als je een website hebt van een paar miljoen pagina’s? Zelfs met een goede categorie structuur kunnen je hoofdproducten alsnog ver weg van je thuispagina terecht komen. In dit geval zou je kunnen overwegen om ‘geslepen navigatie’ te implementeren, wat hierbij kan helpen. Geslepen navigatie past zichzelf aan wat de gebruiker zoekt en elimineert een hoop ruis door hun gemakkelijk te laten filteren om te vinden wat ze zoeken.
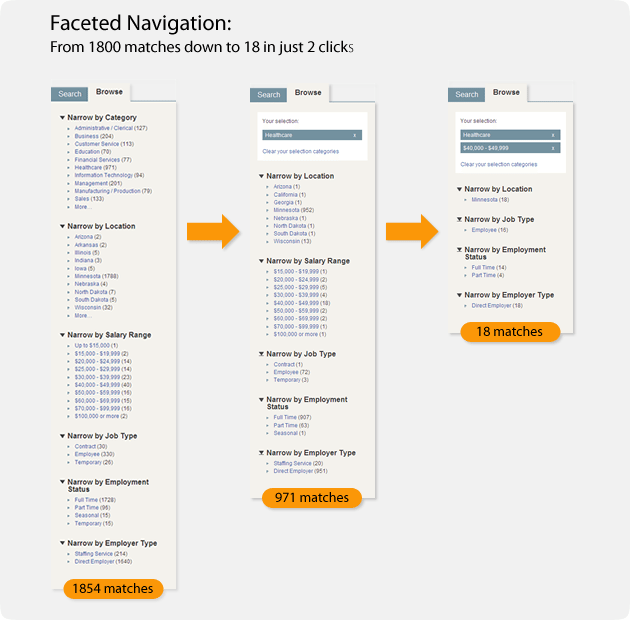
Zoals je kunt zien is het voor een gebruiker zeer eenvoudig om een groot aantal resultaten te filteren door te klikken op de attributes die ze zoeken. Dit is zeker voor e-commerce websites een geweldige techniek, aangezien er gewoonlijk allerlei product attributen zoals maat, kleur en merk zijn waarop je de gebruiker wilt laten filteren. Dit is hoe grote websites het makkelijk kunnen maken voor gebruikers en zoekmachines om snel bij diepe pagina’s te komen.
Met betrekking tot crawlen is er nog een ander ding om op te merken. Soms wil je niet dat de zoekmachines te diep kunnen crawlen en pagina’s vinden die te veel attributen hebben. Stel, we verkopen outdoor kleren en we leggen de focus op jassen. Een jas kan dan de volgende attributen hebben:
- Kleur
- Maat
- Geslacht
- Merk
- Prijs
- Waterbestendig
Nu weten we dat een zoekwoord zoals ‘waterbestendige jas voor mannen’ een redelijk zoekvolume heeft van de AdWords Keyword Planner Tool. Daarom willen we een pagina hebben die de zoekmachines kunnen crawlen, indexeren en ranken van dit zoekwoord. Dit zouden we dus mogelijk maken via onze geslepen navigatie door onze links makkelijk vindbaar te maken.
Aan de andere kant heeft een zoekwoord zoals ‘zwarte grote waterbestendige jas voor mannen onder €100’ niet veel zoek volume. Dus we willen ervoor zorgen dat zoekmachines deze pagina niet kunnen crawlen en indexeren. Maar uiteraard wel beschikbaar voor gebruikers, wanneer ze onze navigatie gebruiken.
Waarom je hier zorgen over maken? Het concept crawl budget of crawl allowance komt hier in het spel en zal door mij besproken worden in het volgende gedeelte. Hieronder zal ik ook bespreken hoe we kunnen voorkomen dat bepaalde pagina’s geïndexeerd of gecrawld worden.
Crawl budget
Google kent een crawl budget toe aan elk domein dat ze crawlen. Volgens Matt Cutts wordt dit budget grofweg bepaald door het aantal PageRank dat je hebt. Ook al wil Google zoveel mogelijk content vinden als ze kunnen, ze hebben maar een bepaald aantal resources om het altijd groter wordende web te crawlen. Dus ze zullen moeten prioriteren en een beetje selectief moeten zijn om ervoor te zorgen dat ze in ieder geval zo veel mogelijk ‘goed spul’ crawlen. Matt geeft aan dat er echter niet echt een beperking is op het aantal pagina’s dat ze zullen indexeren van één domein. Ik begrijp hieruit dat hij zegt dat Google zoveel mogelijk zal crawlen en indexeren van je website als ze kunnen, maar als je PageRank niet echt hoog is, zal het voor hen langer duren om door alles heen te gaan en de diepere pagina’s in je site te vinden.
De crawl beheersen
We weten dat je meer kwaliteitslinks kunt bouwen in je website die helpen bij je PageRank, dat is iets wat sowieso moet gebeuren. Maar je kunt je crawl budget optimaliseren door een paar stappen te nemen om Google zachtjes in de juiste richting te duwen tijdens het crawlen:
- Voeg de rel=”nofollow” tag toe aan links naar pagina’s waarvan je niet wilt dat ze gecrawld worden.
- Maak de links moeilijker voor Google om te volgen door ze te baseren op Javascript of Ajax – wees voorzichtig hiermee want je wil wel dat de gebruiker er nog op kan klikken en Google wordt steeds beter in het crawlen van deze technologieën.
- Block bepaalde sets van pagina’s in je robots.txt bestand zodat Google ze niet crawled.
Het doel van dit alles is niet om PageRank te beheersen, maar om te beheersen aan welke pagina’s je crawl budget wordt besteed. Het is zonde als Google al het crawl budget besteed aan pagina’s die het niet waard zijn. Je wilt liever dat ze tijd besteden aan het crawlen van de pagina’s waarvan je wilt dat ze een hoge ranking krijgen en die vaker geüpdatet worden. Een bijproduct hiervan echter, is dat PageRank zowel in je belangrijke pagina’s als de pagina’s die een hoge ranking moeten krijgen stroomt. Dit kan echter toch bereikt worden door een goede website architectuur te hebben.
Buiten rel=”nofollow” en robots.txt kun je ook META-tags gebruiken om te beheersen hoe Google je website crawled. Deze worden geplaatst in de <head> sectie van de pagina en kunnen een aantal dingen doen waaronder:
- Google vertellen de pagina niet te indexeren
- Google vertellen de pagina nu te crawlen en de links op deze pagina nu te crawlen
- Google vertellen de afbeeldingen op deze pagina niet te indexeren
- Google vertellen geen snippet van de pagina in hun zoekresultaten te gebruiken
- Combinatie van bovenstaand
Onthoud dat deze tags per level zijn en alleen invloed hebben op de pagina zelf. Een ander belangrijk punt om te onthouden is dat de zoekmachines toegang tot de pagina zelf nodig hebben om deze tag te zien. Dus als je een pagina blokkeert in robot.txt, zullen de zoekmachines deze site waarschijnlijk nooit crawlen en de META-tag die eraan hangt nooit zien.
En de rel=”canonical” tag dan? Dit stelt website eigenaars in staat om een canonical versie van een pagina te specificeren en een dubbele of vrijwel dubbele content te markeren, waardoor zoekmachines een signaal krijgen welke pagina’s ze beter wel of niet zouden crawlen, indexeren of ranken. Hou er hierbij rekening mee dat deze tag geen directive is, wat betekent dat zoekmachines zelf kunnen bepalen wat ze met de tag doen en deze kunnen negeren als ze willen.
Deze tag helpt je om te garanderen dat je dubbele content niet schadelijk voor je website zal zijn en ervoor te zorgen dat de juiste URL in de zoekresultaten aan gebruikers getoond wordt. M.b.t. crawlen zou het ook nuttig zijn als de tag zoekmachines zoveel mogelijk weg hield van dubbele pagina’s. Maar net als met de META-robots tag moeten zoekmachines toegang tot een pagina hebben voordat ze de tag kunnen vinden.
Server logs
Als je geavanceerd te werk wilt gaan in het uitzoeken hoe de zoekmachines jouw website crawlen en of er problemen zijn kun je een diepe duik nemen in de server logbestanden om meer gedetailleerde informatie te krijgen. Je server logbestanden worden gevuld zodra pagina’s gecrawld worden door zoekmachines (en andere crawlers) en ook bij bezoeken van mensen. Je kunt deze log bestanden filteren om te zien hoeveel Googlebot precies heeft gecrawld van jouw website. Dat kan je een geweldig inzicht geven in welke pagina’s het meest gecrawld worden en nog belangrijker, welke helemaal niet gecrawld lijken te worden.
Dit is vermoedelijk een van de beste indicatoren die je kunt krijgen van wat een pagina verhindert om geïndexeerd of gerankt te worden. Je kunt allerlei on-site analyses doen, maar als je uiteindelijk in de logbestanden kunt zien dat een site niet gecrawld wordt, dan heb je je antwoord. Dan kun je beginnen met uit te zoeken waar het probleem zit en aan een oplossing werken.
Ik gebruik graag Splunk voor de analyse van logbestanden, het kost wat tijd om eraan te wennen, maar het is zeker een van de betere tools die ik gebruikt heb.
Indexeren
Zodra je tevreden bent dat de zoekmachines je website goed crawlen, is het tijd om te controleren hoe je pagina’s werkelijk worden geïndexeerd en actief te controleren of er problemen zijn.
Bufferen
De makkelijkste manier om te controleren of Google een pagina correct indexeert is om de gebufferde versie te vergelijken met de werkelijke versie. Er zijn drie manieren om dit snel te doen.
- Voer een Google search uit:
- Klik door op de Google search resultaten
- Gebruik een bookmarklet
Ik gebruik een simpele bookmarklet in Chrome om de buffer van een pagina waarop ik me bevind te controleren. Maak een nieuwe bookmark in je browser aan en voeg dit als de locatie toe:
“javascript:location.href=’http://www.google.com/search?q=cache:’+location.href” (zonder de aanhalingstekens)
Gemakkelijk en eenvoudig!
Het doel van het controleren van de buffer van de pagina is:
- Controleren of een pagina regelmatig gebufferd wordt
- Controleren of het buffer al jouw content bevat
Als dit allebei okay is, dan weet je dat een pagina goed gecrawld en geïndexeerd wordt.
Sitemap segmentatie
Hierover is al een aantal maal geschreven dus ik zal hier niet alles herhalen. Om hier een korte samenvatting te geven, het idee is dat door verschillende sitemaps aan te maken voor verschillende delen van je website, je indexering kunt controleren door middel van Search Console.
Index status
Een andere fijne feature van Search Console is index status. Dit geeft je inzicht in hoe Google je website crawled en indexeert en tevens geeft het je een idee over hoeveel pagina’s Google besluit om niet te indexeren.
Als je constant nieuwe pagina’s toevoegt aan je website en je ziet een structurele en langzaam maar zekere vermeerdering in de pagina’s die geïndexeerd worden, dan betekent dit waarschijnlijk dat ze correct gecrawld en geïndexeerd worden. Als je daarentegen een grote (onverwachte) dip ziet, dan kan dit betekenen dat er problemen zijn en dat de zoekmachines je website niet goed kunnen bereiken.
Ranking
Nu het laatste gedeelte van ons werk, mogelijk het stuk dat we allemaal eigenlijk het belangrijkste vinden! Is de ranking van onze pagina’s zo goed als hij zou kunnen zijn? We willen er altijd al voor zorgen dat de ranking van onze pagina’s hoger wordt dan hij al is, dus ik wil hier juist de aandacht vestigen op een zeer specifieke tactiek.
Ten eerste moet duidelijk zijn naar hoeveel pagina’s je verkeer wilt verkrijgen. Dit is vermoedelijk je homepage, categorieën, producten en content pagina’s. Afhankelijk van de manier waarop je website gebouwd is, kan dit op een aantal manieren:
- Kijk naar het aantal URL’s in je sitemap (er vanuit gaande dat je sitemaps up to date en accuraat zijn)
- Praat met je developers die je een globaal idee zouden moeten kunnen geven
- Je kunt ook je website crawlen, maar dit hangt af van of je pagina’s überhaupt toegankelijk zijn
Zodra je dit hebt, moet je controleren hoe veel van deze pagina’s organisch verkeer ontvangen. Dit kun je doen met Google Analytics.
Let erop dat je filtert op alleen organische zoekopdrachten, kies een grote tijdsspanne (tenminste 6 maanden) en scroll naar beneden om te zien hoeveel pagina’s bezocht werden.
Als dit aantal een stuk lager is dan het aantal pagina’s dat je eigenlijk hebt, dan loop je vermoedelijk een hoop potentieel verkeer mis.
Als je een meer accurate indruk wilt hebben en eentje waarmee je ook kunt zien welke pagina’s niet bezocht worden, dan kun je de lijst met URL’s van Analytics exporteren naar een CSV-bestand en deze vergelijken met een lijst van alle pagina’s. Een simpele VLOOKUP zal je laten zien welke pagina’s wel of niet verkeer ontvangen.
Zodra je een lijst hebt van pagina’s die geen verkeer ontvangen kun je verder onderzoeken wat de reden hiervan is. Een paar manieren waarop je dit kunt doen, d.m.v. wat we hierboven bekeken hebben:
- Maak een toegewezen sitemap met alleen deze URL’s en evalueer hoe ze door Google geïndexeerd worden
- Filter je server logbestanden om deze URL’s mee te nemen en te zien of ze gecrawld worden
- Neem steekproeven en controleer de buffer om te zien of ze gebufferd worden
That’s all for today folks. Je hebt nu een aardige kennis opgebouwd wat betreft technische SEO.